
Gartner: Market Guide for Data Masking and Synthetic Data
By Joerg Fritsch, Andrew Bales
Privacy and test data use cases have been addressed by niche data masking controls for years. As it matures, the data masking market is consolidating controls into data security platforms. This research helps security and risk management leaders understand the market evolution for data masking uses.
Overview
Key Findings
Interest in static data masking (SDM) and dynamic data masking (DDM) remains robust across various geographies and industries and is expected to continue growing through 2030, driven by expanding privacy laws, advanced analytics, artificial intelligence/machine learning (AI/ML) projects and zero-trust requirements.
DDM is gaining interest for its fine-grained data authorization capabilities, particularly in cloud-based data lakes. DDM combined with attribute-based access controls (ABACs) is becoming a key feature of data security platforms (DSPs), simplifying data authorization in complex environments with numerous roles.
SDM vendors frequently lack advanced capabilities such as synthetic data generation or differential privacy, which are increasingly requested by end customers.
Recommendations
Security and risk management (SRM) leaders responsible for the security of applications and data should:
Treat data masking (DM) as a foundational control for data security hygiene. If applicable, integrate DM capabilities into your IT service management or into the standardized creation of data products.
Reduce complexity by adopting DDM capabilities included in DSPs or data integration products. This will minimize complexity by reducing the number of database roles and access rules.
Prioritize SDM products that include the creation of synthetic data, synthetic records, events or tabular synthetic data as this can greatly speed up existing test data management processes and enhance security of AI/ML model training.
Market Definition
This document was revised on 11 November 2024. The document you are viewing is the corrected version. For more information, see the Corrections page on Gartner.com.
Gartner defines data masking and synthetic data as technological capabilities designed to transform or generate data to protect the confidentiality of personal or sensitive source data against compromise, or to accelerate machine learning (ML)-focused use cases.
Data masking and synthetic data are primarily used to decrease or eliminate the risks associated with sensitive source data, while retaining utility of the data. This is necessary to satisfy use cases that require coherent data, as well as for analytics that involve, for example, data aggregation for scoring, model building and statistical modeling.
As use cases evolve, so too do core capabilities, such as the influx of data usage for training ML models. Where confidentiality and privacy are compulsory for sensitive data, such as personal health or personally identifiable information, synthetically generated data provides an alternative to real data. Though data masking and other forms of data deidentification can ensure confidentiality and privacy of sensitive data, synthetic data can be superior to deidentification methods for ensuring confidentiality and privacy in use cases of sensitive data for ML model training, or for provisioning test data in software development.
Synthetic data generation also allows for accelerated or timely generation of privacy-preserved data for AI development, and enables effective DevSecOps where real — or masked — data cannot be made available at the necessary speed, or is too expensive to retrieve.
Mandatory Features
The mandatory features for this market are:
Automated discovery of sensitive data relationships across multiple tables and databases (referential integrity) across at least six distinct structured data stores, with the option to either break data relationships to mitigate reidentification risk or preserve the relationships to maintain consistent masking.
Rule management for consistent data masking rule enforcement across multiple databases, based on the data and relationships discovered or imported.
Deidentification of data ahead of data use (static data masking [SDM]) or deidentification of data at the time of data access (dynamic data masking [DDM]), using anonymization, pseudonymization or redaction methods.
Common Features
The common features for this market include:
Full life cycle management of data masking, including rule deployment, masking job scheduling, masking operations monitoring, and reporting for compliance.
Data integration through data virtualization technologies.
Support for data tokenization or format-preserving encryption.
Integration with data catalogs to curate the generated datasets.
Implementation of defenses against reidentification based on, for example, k-nearest neighbors or k-means clustering.
Possibility to generate small to medium amounts (around 1TB) of synthetic data.
Integrated self-service portal to enable, for example, data scientists or developers to quickly provision the necessary test data.
Market Description
DM protects sensitive data by providing organizations with a configurable platform that can alter data while maintaining statistical integrity. This ensures that business processes and use cases remain functional and effective (see Figure 1).
Figure 1: A Simple Example of Data Masking
DM can be implemented in four ways, two of which carry the DM name. These options combine specific architecture and data transformation approaches. Each option has its own impact on data security and data utility. The four architecture options are:
Static data masking (SDM) architectures provide wide-ranging data field and dataset transformations and are typically a nonreversible process in which the data undergoes a one-way transformation, usually retaining some degree of original data’s syntax and semantics. These are mostly applied in batch mode during extraction, transformation and loading (ETL) operations that transfer data from one repository into another.
Dynamic data masking (DDM) architectures provide irreversible data field transformations applied in real time. They are designed mainly to transform the data at the time it is requested for extraction or use but can also be used during data ingestion or load.
Tokenization and format-preserving encryption (FPE) architectures provide reversible data field transformations applied in batch processing mode or real time. They are designed to protect data at rest and subsequent use by transforming it before it is stored in a repository and by providing a real-time service to obtain the original data when needed.
Synthetic data refers to generated data that mimics real data. Synthetic data complements or replaces real data to tackle data security and compliance concerns, as well as address the challenges of insufficient data in the adoption of AI and generative AI (GenAI) technologies.
Architecture choices are not mutually exclusive and may be combined for greater efficacy in some scenarios.
Market Direction
Interest in SDM and DDM remains robust. The number of Gartner client inquiries has seen a notable increase originating from Southeast Asia. The level of interest in North America has declined modestly year over year, with vertical markets that rely on personal data — such as financial services, retail and healthcare — remaining very strong. We expect interest in DM (including DM provided by data security platforms [DSPs]) to continue through 2030 fueled by trends, including:
Steadily increasing interest in SDM (for open data and privacy compliance) and DDM (for zero-trust objectives) from U.S. government agencies and contractors.
Increasing interest in DDM, mostly in combination with ABAC and data catalogs (as offered by some DSPs).
The expansion and maturation of privacy laws in global jurisdictions.
Growth and increased data-security-related awareness of advanced analytics and AI/ML projects, as well as migration of these projects to cloud-based data lakes. (DM is still utilized but becoming less useful in AI/ML projects, giving way to synthetic data and differential privacy.)
Increased attention to protecting data from insiders using, for example, zero-trust principles whereby all access must be precisely defined and authorized. (This trend is supported well by the combination of DDM and ABAC capabilities that are frequently available in DSPs.)
DM solutions are highly effective for protecting personally identifiable information (PII). However, end users seeking to deidentify sensitive information, such as chemical formulas or other critical intellectual property, often find that commercial off-the-shelf products fall short of their needs. Gartner observes that mature end customers who need to mask sensitive information that is not PII are frequently using products that generate vertical-specific or custom-made synthetic data.
While many DDM vendors have successfully reinvented themselves as data authorization tools and DSPs, many SDM vendors and products frequently continue to fall short in addressing customer requirements for privacy-enhancing computation capabilities. Examples include differential privacy or the generation of tabular synthetic data, which end customers have been requesting for almost a decade now. Gartner observes that in many cases these capabilities are available from startup companies that are frequently not active in the traditional SDM market.
Market Analysis
Table 1 shows the applicability of the four architecture options. Low applicability means the architecture is not in common use for this use case, because it neither provides enough protection nor fits with the use case’s common data and application architectures. Medium applicability means the architecture is used in specific subsets of a use case but requires careful evaluation against requirements to determine its fitness. High applicability means the architecture is in common use because of its effectiveness (although limitations may still be present).
Table 1: Applicability of Deidentification Architecture Options to PII and Protected Health Information Data Field Types
DM implementation is typically an exercise in compromise between confidentiality and usability. With the diversity of masking algorithms and approaches, DM alone is not guaranteed to meet requirements for a given use case’s confidentiality and usability. This is because the transformations necessary to meet confidentiality requirements might render the data unusable in the business processes and applications.
Application types and applications have varying requirements for maintaining data context or data utility (that is, how “realistic” the masked data needs to be compared with the original). Some environments require nothing but the real data, while others can function with heavily distorted and randomized data. In general, the more knowledge that is embedded in the data and is required or produced by the applications, the higher the utility requirements.
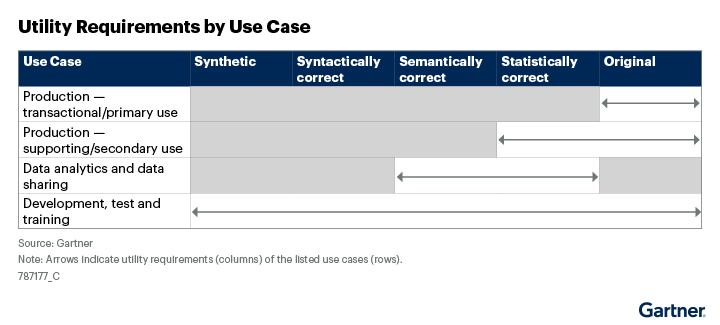
As reflected in Figure 2 for analytics, modeling and testing, this breaks down into several conceptual categories of increasing need for more realism. Determining the category for a specific use case is an artistic or trial-and-error exercise; here is no one measure of data utility.
Figure 2: Utility Requirements by Use Case
Static Data Masking
The heightened interest in SDM is driven by the necessity for development and testing data, such as in user acceptance testing environments, as mandated by numerous privacy regulations. Clients value SDM products that incorporate comprehensive test data management features, including data subsetting, self-service portals, data integration capabilities (e.g., data virtualization), and the amalgamation of datasets and masking rules into data products. These are frequently managed as IT services using frameworks like information technology infrastructure library (ITIL), IT service catalogs and internal service-level agreements.
Despite being frequently discussed, Gartner observes that the risk of residual data reidentification and its mitigation often do not significantly influence client decisions; though, arguably, they should. Currently, the market offers only a limited number of SDM products that provide insights into reidentification risk, highlighting a gap that needs addressing.
In recent years, the on-premises SDM market has become increasingly diverse, with several midmarket products gaining traction and acceptance within large enterprises. While tokenization products that implement DM capabilities temporarily enjoyed significant popularity in the SDM market, they now primarily appeal to clients requiring tokenization for compliance purposes or reversible DM — representing only a small segment of the market.
In cloud-based environments and data lakes, traditional SDM products have diminished in relevance. This shift is partly due to cloud service providers offering APIs that support DM, such as Google’s Cloud Data Loss Prevention (DLP) API, or providing DM solutions and architectures like Amazon Web Services (AWS) Database Migration Service and AWS Glue.
Additionally, clients in cloud-based data lakes, such as Databricks or Snowflake, prefer to mask their data without creating curated copies, leading to a prioritization of DDM or products that offer advanced data integration and data virtualization capabilities.
Dynamic Data Masking
While traditional DDM use cases — such as the suppression of the first 13 digits of a 16 digit credit card number in a call-center application — remain strong, new DDM products are frequently extended with ABACs and data governance capabilities, such as data catalogs. The use of DDM controls as a means to enforce data authorization on the field level combined with organizations’ need for fine-grained data authorization in (cloud-based) data lakes gave rise to DSPs. For more information, also read Market Guide for Data Security Platforms.
At this time, approximately 15 years after DDM was first introduced to the market, DDM sees an unprecedented interest and update in the form of fine-grained data authorization capability. DSPs with DDM have strong momentum for data authorization in environments where clients need to simplify or speed up data authorization — for example in environments that have more than 100 to150 role-based access control (RBAC) roles. That is environments where ABAC in combination with data catalogs can lead to considerable simplification.
DDM is also very strong in client architectures where clients need DDM and, at the same time, value data integration features to support the fast and compliant creation of data pipelines for (training) AI or supporting DevOps teams. For additional information on the role of DM and other technologies in the AI data pipeline, see Securing Your AI Data Pipeline.
Tokenization and Format-Preserving Encryption (FPE)
Tokenization and FPE architecture protects a data field by replacing its value with a substitute when it is loaded into an application or data store. This protects data at rest, as well as data in subsequent use. If an application or a user needs the real data value, the substitute can be transformed back because the algorithms are designed to be reversible. The algorithms are designed to provide a unique and consistent mapping between the real value and the token, which makes them applicable to directly identifying data fields.
Vendors frequently position FPE as a complete alternative to DM products. However, compared with leading DM products, the options for adjusting the output of FPE products are limited. FPE is frequently limited to the generation of primary account numbers that pass the Luhn check,2 n-bit numbers and, very rarely, English words. DM variance, such as the transforming of dates of birth into dates of birth from a specified range that remains meaningful for analytics use cases is frequently not supported.
Synthetic Data Capabilities of DM Products
End customers are frequently investigating synthetic data to make provisioning of data for training AI or DevOps teams even faster. Despite the high potential that synthetic data promises, DM vendors and products rarely implement state-of-the-art capabilities to generate tabular synthetic data. Most vendors listed in the Market Guide offer products limited to generating small amounts of synthetic PII, for example, a few megabytes of credit card numbers that pass validity checks or social security numbers. While useful, this generally does not meet end-customers’ requirements and does not bring them into a position to reap the potential security benefits from synthetic data.
Representative Vendors
The vendors listed in this Market Guide do not imply an exhaustive list. This section is intended to provide more understanding of the market and its offerings.
Vendor Selection
Representative DM vendors generally provide support for the full life cycle of a DM implementation, as well as enterprise manageability features. However, they also include vendors that have made significant steps in that direction, as well as platform vendors that have introduced DM functionality and are expected to make an impact on the DM market.
Table 2: Representative Vendors in Data Masking
Vendor Product, Service or Solution Name
Accelario Accelario Platform
Accutive Accutive Data Discovery and Masking (ADM Platform)
ARCAD Software DOT Anonymizer
Ankki Technology Static Data Masking, Dynamic Data Masking
Anonos Data Embassy
Baffle Baffle Data Protection Services (DPS)
Beijing DBSEC Technology (DBSEC) DBSEC Data Masking System (DMS)
Broadcom Test Data Manager
ChainSys dataZense
comforte comforte Data Security Platform
DataSunrise Static Data Masking, Dynamic Data Masking
DATPROF DATPROF Privacy
Delphix (by Perforce) DevOps Data Platform
IBM IBM InfoSphere Optim Data Privacy
Immuta Dynamic Data Masking
Informatica Cloud Data Masking
Innovative Routines International (IRI) IRI FieldShield, IRI DarkShield, IRI CellShield
IQVIA (Privacy Analytics) Eclipse Risk
K2View Data Masking, Synthetic Data Generation
Kron Dynamic Data Masking
Libelle IT Group Libelle DataMasking
Mage Data Mage Static Data Masking, Mage Dynamic Data Masking
Microsoft SQL Server
Mostly AI Tabular Synthetic Data
NextLabs Dynamic Data Masking for SAP ERP
OpenText Voltage SecureData
Oracle Oracle Data Safe
Pangeanic Data Masking Tool
PKWARE PK Protect
Prime Factors EncryptRIGHT
Privacera Data Security and Access Governance Solution
Private AI Private AI
Protegrity Protegrity Data Protection Platform
Redgate Data Masker
Satori Cyber Dynamic Data Masking
SecuPi SecuPi Platform
Snowflake SnowFlake Dynamic Data Masking
Solix Technologies Solix Enterprise Security and Compliance
Tata Consultancy Services (TCS) TCS MasterCraft for data management
Thales CipherTrust Data Security Platform
Velotix Data Security
Source: Gartner (August 2024)
Market Recommendations
When approaching DM technology, SRM leaders should consider these pragmatic realities:
Treat DM as an important control for data security hygiene. DM is a crucial component of data security hygiene, integrated into many data security products and platforms. It is essential for creating secure development and test data (SDM) and serves as a late-binding access control to conceal data based on request context, including DDM, field-level authorization, FPE and tokenization. For organizations in heavily regulated industries, DM is a baseline control necessary to secure sensitive data and comply with stringent regulations. Ignoring DM could lead to severe repercussions from regulators, customers and stakeholders, further damaging an organization’s reputation in the event of a data breach.
Reduce complexity by adopting DDM capabilities included in DSPs or data integration products. For most use cases, several data security controls and technologies will be required to address data security and data integration requirements. Matching several requirements with the capabilities of a DSP can considerably reduce complexity. For example DSPs that integrate DDM with capabilities like data catalogs, ABACs and data classification solutions often reduce the number of roles needed to securely share data from hundreds to just a few dozen.
Prioritize SDM products that include the creation of synthetic data, synthetic records, events or tabular synthetic data. This can greatly speed up existing test data management processes and enhance security of AI/ML model training. Tabular synthetic datasets enable teams to train and test their models against a wide range of possible outcomes, addressing, for example, biases in real-world data. Frequently synthetic data can be rapidly generated and requires less risk considerations and approvals reducing the “time to data.”
Evidence
1 This is a forward-looking evaluation taking into account the potential benefits of synthetic data. However, synthetic data creation with DM products often still lacks maturity and breadth. Thus, the accurate rating would be “Low” for all use cases.
2 A verification algorithm used to validate various numbers such as credit card numbers. It is used by major credit card issuers.